There's a gap that opens up gradually when you move from hands-on engineering into team leadership and management, and it's easy to ignore until it becomes uncomfortable. I've been managing engineering teams in some form since around 2010, and at some point I realized I was regularly recommending tools, making architecture decisions, and evaluating vendors for technology I hadn't personally stood up in years. I could hold the conversation credibly, but the question I kept coming back to was whether I could truly support my team through the hard decisions. Things like defining best practices, the architectural tradeoffs, appropriate pipeline tooling, etc. How could I earn my team's trust and respect if I didn't know the languages, frameworks and tooling that they used on a daily basis?
Certifications can help, though they're better at closing knowledge gaps than building judgment, and what you study for an exam tends to fade unless you're actively using it. Tutorials are useful for syntax and concepts, but you're working through someone else's scenario in a controlled environment, which isn't quite the same as making real decisions on real infrastructure. What actually builds the kind of confidence I was looking for is building something of my own, where the architecture choices are mine, the mistakes land on my own system, and the consequences are proportional to how well I think things through.
Some employers and environments have a dev sandbox you can play around in, but a more holistic solution is to start a project of your own with a high overlap to the tools your teams use on a daily basis - something you're fully accountable for end to end.
Avoiding a failure pattern
In my experience, side projects fail less often because of scope or time than because the subject matter wasn't interesting enough to sustain the effort through the hard parts, and there are always hard parts. Every non-trivial project has a stretch where the dependency you needed has a breaking change, the documentation turns out to be wrong, or the approach you committed to three weeks ago has a fundamental flaw you're only now seeing. If the subject matter itself doesn't have genuine pull for you, that's when the repository stops getting opened.
This is something I've thought about a fair amount: the technology stack matters much less than the domain in which you're building. An engineer who's genuinely curious about self-hosting and home lab infrastructure (for example) will push through the frustrating parts of a project in that space in a way they simply won't for a generic to-do app. The subject matter is what keeps you coming back, and without that even a well-scoped project tends to drift.
So before I describe what I ended up doing, I'd offer this as a starting point for anyone in a similar situation: think about what you'd read about or watch or talk about even if there was no code involved. The newsletters you actually open, the subreddits you check regularly, the topics you find yourself explaining to people at lunch or over dinner. Those are your candidate domains for a project that will hold your attention long enough to compound into something real. If nothing comes to mind immediately, here are a few directions I considered before landing on my own answer: self-hosting and home lab infrastructure, electric vehicles, investing for early retirement, home improvement and automation, and animal rescue. I'm not suggesting any of these specifically, just illustrating that the right domain is personal, and that the list of viable options is a lot broader than "build a SaaS product."
A project worth committing to tends to have three characteristics:
- Enough real operational complexity to force genuine decisions about infrastructure, reliability, and cost;
- Low enough stakes that failing safely is an option while you're learning; and
- (Most Importantly) A subject matter that holds intrinsic interest regardless of the technology involved. If it eventually turns into something more than a learning exercise, that's a fine outcome, but it shouldn't be the goal going in. It really just needs to be interesting and fun.
So what worked for me?
In 2005, I co-founded hdtvmagazine.com with a gentleman named Dale Cripps, who had been running a daily hand-curated email newsletter since the late 90s about HDTV programming. HDTV was something I'd been following closely since seeing it for the first time at Epcot in the mid-nineties, and when Dale and I connected, it seemed natural to turn his subscriber base and my programming background into something more structured. We built the site as a programming guide and editorial destination for early adopters, at a time when figuring out what was actually on in high definition required real effort, and over the years we added authors, a community forum, equipment reviews, and more. At its peak the site was doing close to a million visits a month.
 hdtvmagazine.com at its peak, circa 2005.
hdtvmagazine.com at its peak, circa 2005.
Traffic waned as HDTV matured from novelty to table stakes, the ad dollars that had supported the site dried up, and by around 2012 we decided to wind things down. Dale had already retired and was spending his time traveling; I had a career and a family pulling in other directions. I kept the domain because domains are cheap and I had a vague sense that someday I might do something with it.
When I finally decided to bring the site back, the motivation was straightforward: I had a real codebase with twenty years of history, 4,000 articles in a database, a domain with actual search equity, and a subject matter I'd genuinely cared about for decades. Starting a new side project from scratch would have meant inventing a reason to care. This one already had all the ingredients, including the rough edges, and there were plenty of those.
 The site today - same domain, rebuilt from scratch.
The site today - same domain, rebuilt from scratch.
What I actually wanted to learn
The three areas in which I was most motivated to develop hands-on experience were:
AI in actual use, not just as a conversational tool. I'd been using tools like Claude and ChatGPT regularly, but I wanted to understand what it looks like to build AI into a product rather than use it as a chat interface. A content-heavy site is a natural fit for this: there are obvious applications in metadata generation, content classification, feed card excerpts, and SEO descriptions at scale. Specifically, I wanted real experience with AWS Bedrock, understand what it actually is underneath the surface, and run genuine inference workloads against a real content corpus. The 4,000 legacy articles in the database were exactly the kind of raw material I needed.
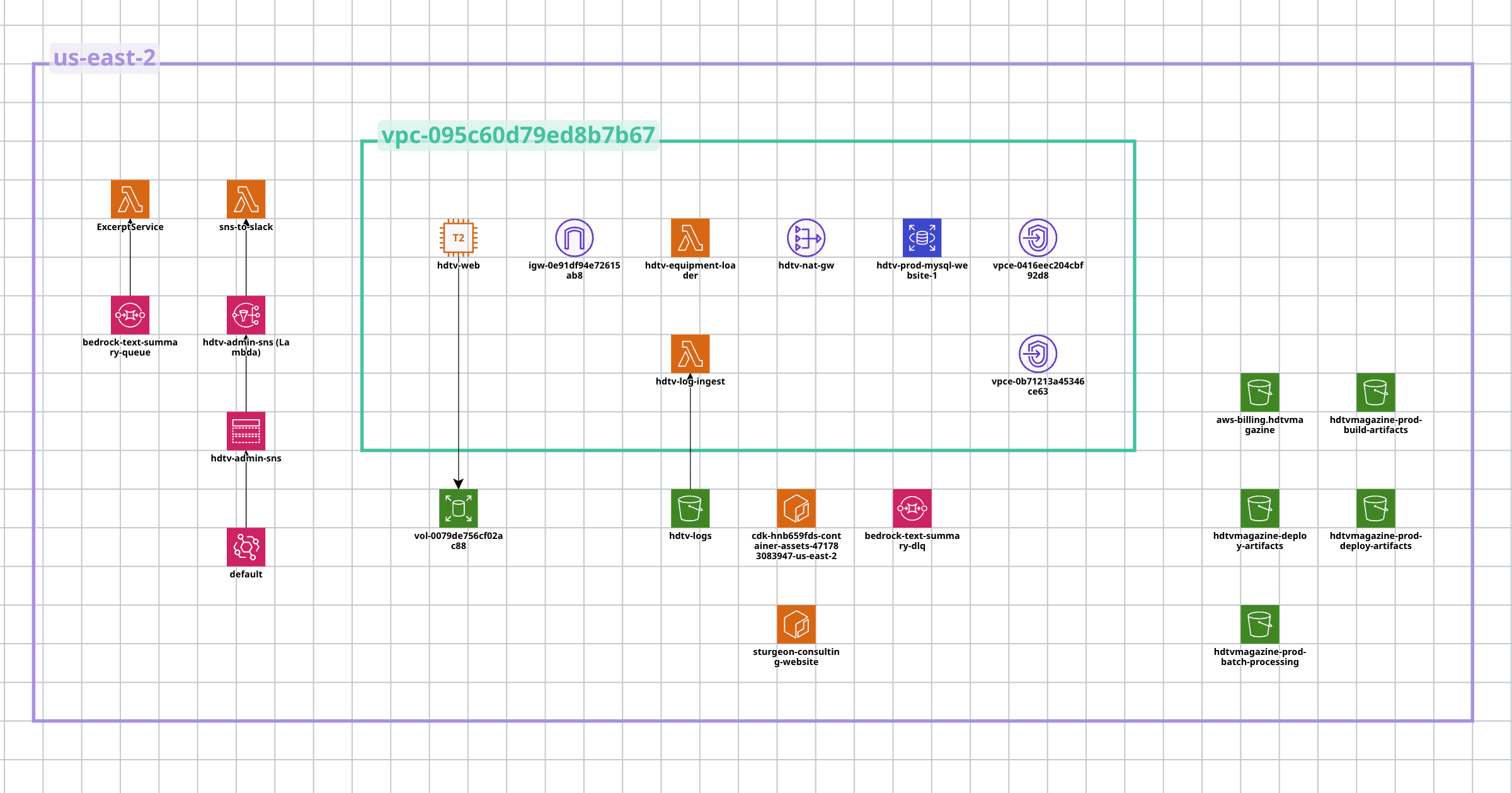
AWS architecture as a designed system, not a collection of individual services. I had prior experience with isolated AWS services, EC2 and SQS among them, but I hadn't designed and operated an architecture that used them together in a coherent way. What I wanted to build was a proper VPC with private subnets, RDS as a managed database layer, Lambda for event-driven workloads, EventBridge for orchestration, and SNS for operational notifications. The site didn't require any of this to serve its current traffic levels, and that was fine: the point was learning what these services actually do when you wire them into a real system, at a cost I was consciously willing to pay for the education. For reference, the full stack runs at around $5 per day, which feels like a reasonable tuition rate for this kind of hands-on learning.
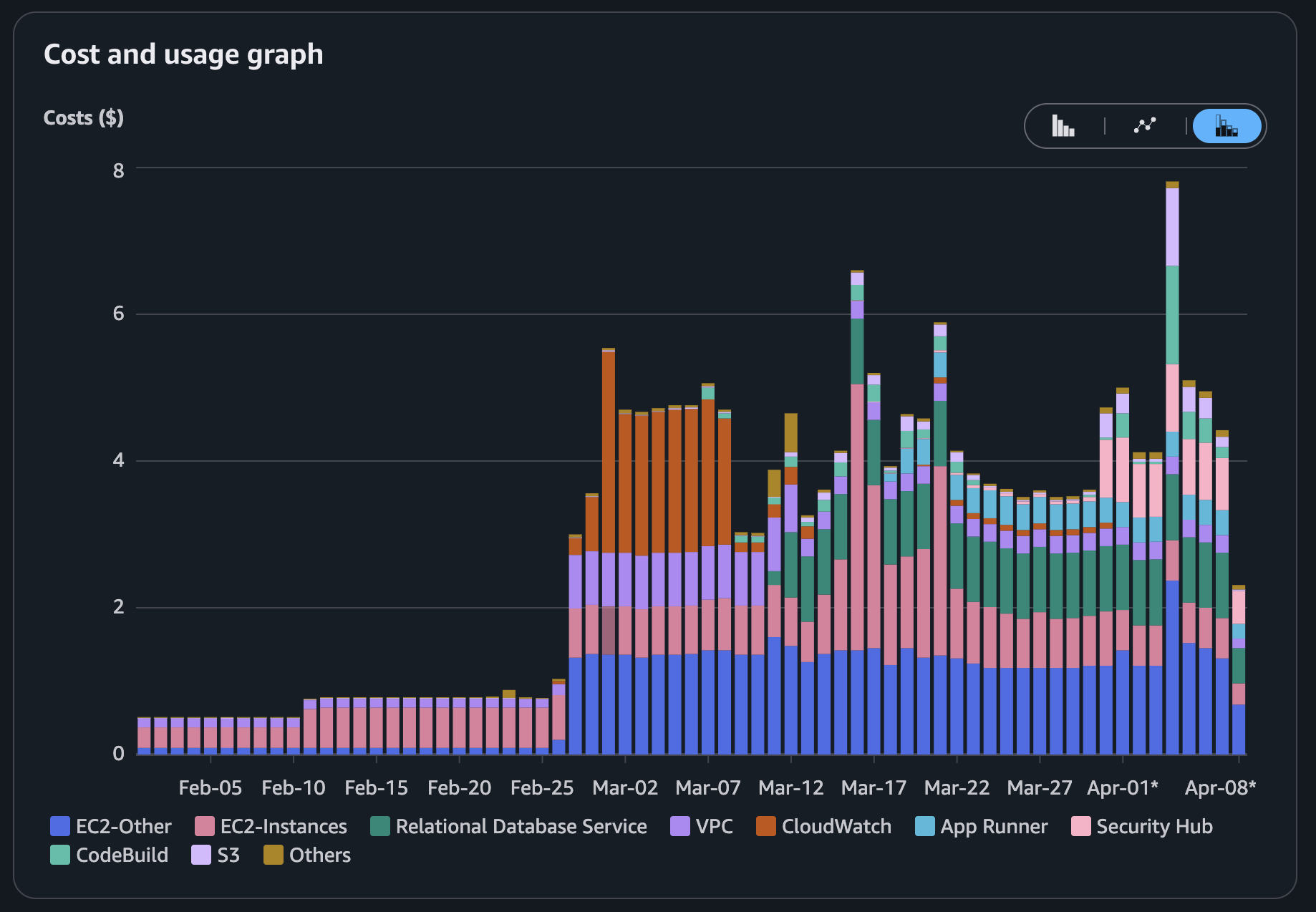 Monthly AWS spend since project start - each step up corresponds to a new service added to the stack.
Monthly AWS spend since project start - each step up corresponds to a new service added to the stack.
Orchestration and DevSecOps tooling, from setup through operation. My teams had been using GitHub Actions, CodeBuild, CodeDeploy, SonarQube, Snyk, and AWS Security Hub as standard practice, and I was making decisions about adoption, rollout, and configuration without having personally set any of it up. I needed a low-stakes environment where I could learn how these tools actually behave before recommending optimizations at scale, which means learning where the defaults are sensible, where they need tuning, and where the documentation understates the complexity. The original site gave me that: a legacy codebase with no existing security tooling, no CI/CD pipeline, and no schema migration discipline, which was a blank canvas for doing all of it from scratch.
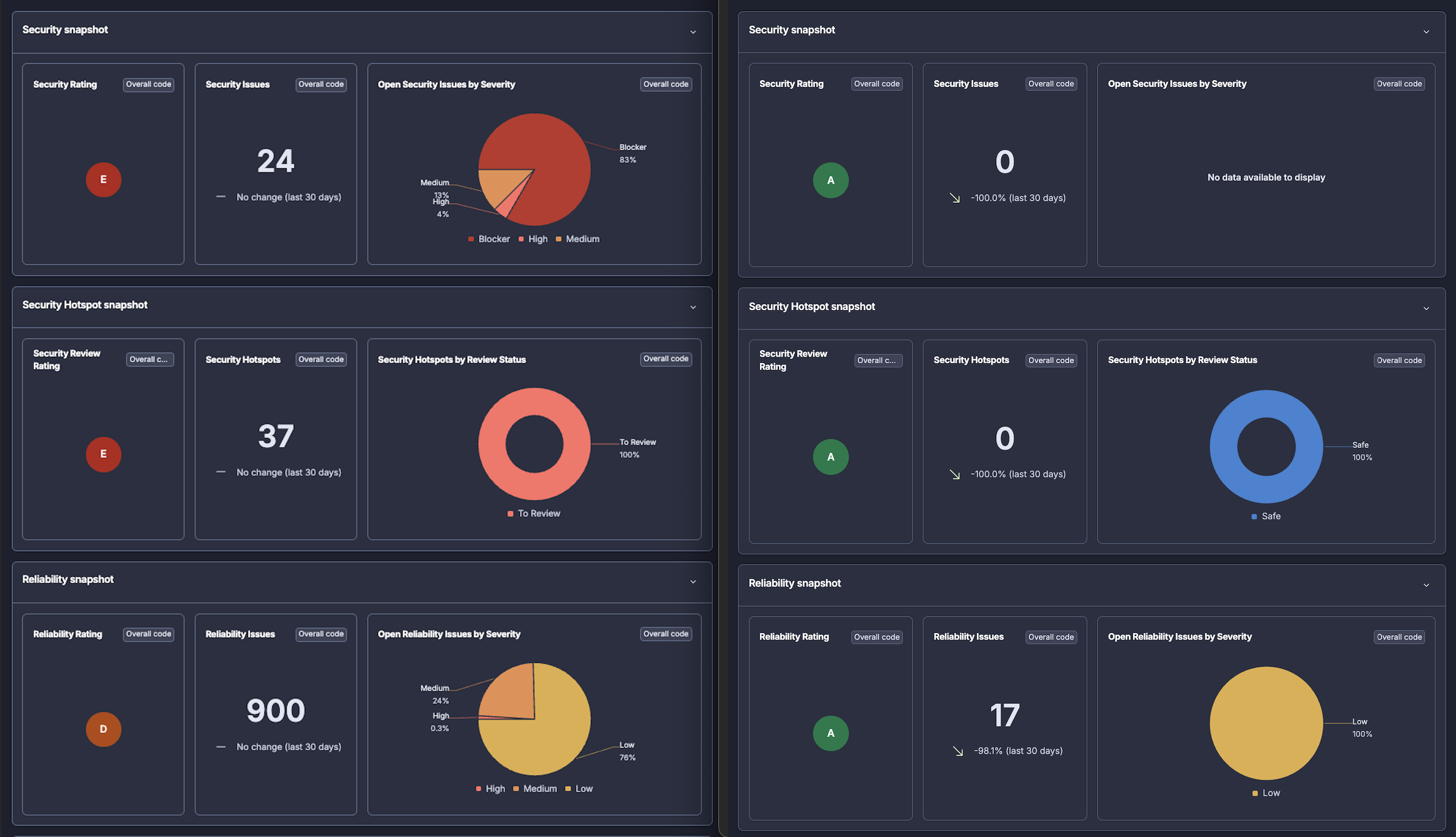 SonarCloud baseline vs. current state. The D and E ratings weren't a surprise given the codebase age - getting to all A's from there is its own story.
SonarCloud baseline vs. current state. The D and E ratings weren't a surprise given the codebase age - getting to all A's from there is its own story.
There were other areas I wanted to explore as well - TypeScript, Python, React, Postgres - though those were more in the "I'll get there when the project takes me there" category rather than primary goals.
What I started with, and where it is now
When I pulled the code out of storage, I was working with a 2005-era codebase that had been maintained through roughly 2012 with no formal engineering process: a single EC2 instance running Apache, MySQL, and PHP 5, with no version control, no CI/CD pipeline, no schema migration tooling, no security scanning, and a deployment process that consisted of editing files locally and FTP-ing them to the server. The database was running on the same EC2 instance as everything else. Scheduled jobs ran via cron. Nobody had run a vulnerability scan on this codebase in a decade, if ever. Looking back at code you wrote more than 10 years ago is … well, an experience.
Getting it working on modern infrastructure took longer than expected, mostly because PHP 5 to PHP 8 is not a graceful upgrade path, and because the database had evolved organically over years without any migration discipline to describe what it was supposed to look like. But that friction was genuinely useful, because working through the upgrade forced me to understand what had broken and why in ways that a greenfield project wouldn't have required.
Here's where the site stands now, and what's coming in the posts that follow this one:
-
CI/CD pipeline: GitHub Actions wired to CodeBuild and CodeDeploy, with proper appspec-driven deployments, artifact management, and deployment notifications via SNS-to-Lambda-to-Slack. No more FTP, and no more guessing whether a deployment succeeded.
-
AWS architecture: RDS for the database (with the EC2 instance right-sized now that it's no longer doing double duty), VPC with private subnets, EventBridge for scheduling, Lambda for event-driven workloads, SNS for operational events. A designed system rather than a single box doing everything.
-
Authentication: Clerk for admin access and user accounts, replacing a hand-rolled auth system that was never going to pass a security review.
-
DevSecOps baseline and remediation: Snyk, Dependabot, SonarCloud, Semgrep, AWS Inspector, and Security Hub, starting from a legacy codebase with no existing coverage and working through to A ratings across all quality and security dimensions. The before and after here are significant, and that story gets its own posts.
-
Algolia search: Modern search on a legacy content library, replacing what MySQL full-text search was doing (or failing to do) before.
-
AI batch inference: AWS Bedrock generating SEO metadata across 4,000 legacy articles, including model selection, batch pipeline design, and cost analysis.
-
Database migration discipline: Flyway for schema management on a project that had never had any, including patterns for embedding data migrations atomically alongside schema changes.
-
Structured data: JSON-LD for Article, Organization, and Person schemas, and what that actually does for search visibility.
-
URL health monitoring: A logrotate-to-S3-to-Lambda pipeline for analyzing Apache access logs, surfacing 4xx/5xx patterns, and tracking URL health over time without paying for an observability platform.
-
Image optimization: WebP conversion with transparent Apache content negotiation, and lazy loading for below-fold images.
Each of these is its own post with real decisions, real problems, and actual before-and-after outcomes. The series will be running for a while.
What's still on the list
The honest answer is that the project generates more things to learn than I'm finishing, which is either a sign that I picked well or that I have a problem, possibly both. A few things still on the list that haven't made it into the stack yet:
- Blue-green deployments: Something I've supported for years but haven't implemented myself, and this seems like the right environment to actually build one.
- CDN layer: CloudFront would be a meaningful addition for performance, and there's a real story in how S3 fits into a hybrid PHP/static-asset architecture.
- Event-driven services: Kafka or something in the event-driven messaging space would be a useful stretch, especially as the site's data pipeline grows more complex.
- Automated testing and code coverage: Something I've conspicuously avoided so far, which means I'll have to reckon with it eventually.
And there are languages and databases I've been meaning to get hands-on with - TypeScript beyond the sitegen work, Python more seriously, Postgres instead of MySQL - that will find their way in as the project creates natural opportunities.
The site is live at hdtvmagazine.com. The content is archival, the platform is modern, and the backlog is long.